En rédigeant le P.S. sur SYSTRAN des acteurs du marché de la traduction technique en France, l'idée m'est venue de faire le point sur l'état de la Traduction Automatique (TA). Car voici déjà huit ans que j'en parle sur Internet, et notamment du binôme Google + TA (pdf), en expliquant alors que l'ambition de la TA (née il y a plus de 80 ans !) précédait la création d'Internet :
De la machine à traduire au phonétographe (ancêtre de la dictée vocale), les premières recherches sur la traduction automatique datent de l'après-guerre et précèdent de plus d'une décennie le développement d'Arpanet.
Selon Jacqueline Léon, le « mythe de la machine à traduire précède l’apparition des ordinateurs et les premières machines à traduire remontent aux années 30 notamment avec la machine du soviétique Troianskij. »
D'après John Hutchins, c'est en 1933 que Petr Trojanskij, russe, et Georges Artsrouni, russe nationalisé français, qu'il considère comme des précurseurs, auraient déposé un brevet sur la TA, respectivement en Russie et en France.
Toujours à propos des machines à traduire de ce dernier :
Inventée et construite par Georges Artsrouni entre 1932 et 1935 cette machine fonctionne en effet comme un lexique automatique. Le Musée des Techniques, du Conservatoire des Arts et Métiers, l'a acquise au début de l'année 1964 et tous les documents recueillis à cette occasion ont été remis au Centre de Documentation d'Histoire des Techniques. En raison du développement des travaux sur la traduction automatique et de la place que cette nouvelle technique est appelée à prendre à plus ou moins longue échéance dans l'activité quotidienne, il n'est pas déraisonnable de penser que la machine Artsrouni pourra être considérée plus tard comme une pièce historique de grande valeur.
(...)
Nous ne savons pas si la machine de P. P. Smirnov-Trojanskij a été réalisée. Elle n'est sans doute restée qu'à l'état de plans et de description ; le projet n'a pas été pris en considération par les autorités soviétiques responsables bien qu'il ait été présenté à deux reprises en 1933 et en 1944 (Delavenay, La machine à traduire). Le mémoire a été publié par l'Académie des Sciences de l'U.R.S.S. en 1959.
L'invention de Georges Artsrouni a été poussée beaucoup plus loin que celle de Trojanskij. L'inventeur, devenu Français, a en effet construit deux machines et mené très loin la construction d'une troisième. Chacune de ces machines constituait un état beaucoup plus perfectionné de l'invention que la précédente.
La première machine a été construite probablement en 1932. Elle a été détruite plus tard et aucun document la concernant n'a été conservé ; nous n'en connaissons qu'une photographie qui ne permet pas d'en donner une description ; mais on peut se rendre compte qu'elle devait posséder tous les éléments essentiels de la seconde machine dont elle constituait sans doute un prototype.
La deuxième machine a été construite à partir de 1933 ; elle était achevée probablement en 1935, elle a été présentée à l'Exposition Universelle de 1937. C'est cette machine que le Musée des Techniques a acquise ; nous en donnerons une description sommaire plus loin.
En 1935 Georges Artsrouni déposa un brevet français pour « un appareil rendant mécanique et automatique l'emploi d'horaires de chemins de fer, d'annuaires téléphoniques, de dictionnaires, etc. ». La description et les planches qui constituent ce brevet correspondent à la troisième machine et aux éléments complémentaires inventés pour son utilisation pratique. Ce brevet, déposé sous la forme d'un paquet cacheté, a été retiré par l'inventeur un an plus tard (août 1936). A ce moment la construction de la troisième machine devait être commencée. Peut-être, bien qu'inachevée, a-t-elle été aussi présentée à l'Exposition de 1937.
L'inventeur a écrit dans une notice dactylographiée sur lui-même : « Quelques machines de son invention ont été exposées à l'Exposition Nationale de Paris en 1937 et leur principe a été couronné d'un Grand Prix de cette Exposition. »
Émile Delavenay ( La Machine à traduire, Que sais-je n° 834, PUF 1959) nous donne d'importants détails supplémentaires :
C'est en 1946 que l'anglais A. D. Booth et Warren Weaver de la Fondation Rockefeller abordent ensemble le problème de la traduction.
(...)
En 1949 Weaver ... va beaucoup plus loin, et pose définitivement le problème de la résolution des ambiguïtés sémantiques par l'exploration du contexte immédiat.
Il affirme que les éléments logiques du langage peuvent être traités par les circuits logiques des calculatrices ; que la théorie de l'information de Shannon apporte des lumières d'ordre statistique sur le problème de la traduction ; il recommande notamment, à la lumière de cette théorie, d'entreprendre des études de sémantique statistique. Il pose enfin de façon imagée le problème de la recherche sur la nature même du langage, instrument de communication. Dès janvier 1950, Reifler faisait circuler son étude n° 1 sur la traduction mécanique, première tentative sérieuse par un linguiste d'analyser la préparation des textes écrits aux fins de traduction par une calculatrice. Il avançait la thèse de la nécessité d'une mise au point préalable (pre-editing) des textes à traduire, et d'une révision (post-editing) des textes traduits par la machine.

Ce qui est fort étonnant, dans la chronologie qui précède, c'est de voir que les principes de la traduction automatique statistique que nous connaissons aujourd'hui (y compris les phases de pré- & post-édition) étaient déjà posés il y a ... 65 ans !!!
Et selon l'introduction de M. Delavenay, la traduction automatique, "projet très avancé" à la fin des années 50, était inéluctablement appelé à devenir "réalité demain" :
Depuis 1954 les journaux annoncent périodiquement l'invention ou la mise au point d'une machine à traduire ; informations prématurées, de nature à gêner la recherche, parce qu'elles encouragent dans l'opinion la passivité devant un problème exigeant encore de patientes explorations et la collaboration, dans des tâches nouvelles, de spécialistes peu accoutumés à conjuguer leurs efforts : les linguistes et les ingénieurs de l'électronique. Réalité demain, projet très avancé aujourd'hui, la machine à traduire est virtuellement des nôtres ; nous pouvons faire confiance à l'homo faber, et sans faire du roman d'anticipation étudier ici la genèse, le fonctionnement et les possibilités de cette invention.
Donc le problème n'était pas le "si", mais le "quand". Car ce que tous les analystes de l'époque n'avaient pas prévu, c'est qu'il aurait fallu attendre encore plus qu'un demi-siècle avant que "demain" ne devienne enfin "réalité" !
Déjà, il faudra que dix ans s'écoulent pour que naisse la première entreprise spécialisée dans le développement de systèmes de TA à des fins commerciales :
En 1968, le Dr. Toma crée une société implantée à La Jolla (Californie, États-Unis) avec un logiciel appelé SYSTRAN, un acronyme pour SYStem TRANslation. Peu après, sa société est choisie pour développer le système Russe --> Anglais pour l'US Air Force. Le premier système développé par SYSTRAN est testé au début 1969 sur la base aérienne de Wright-Patterson à Dayton (Ohio, Etats-Unis), et depuis 1970, le système fournit des traductions pour la Foreign Technology Division de l'US Air Force. En 1996, SYSTRAN a ainsi signé un contrat avec l'US National Air Intelligence Center pour développer plusieurs couples de langues d'Europe de l'Est. A l'occasion du conflit en Yougoslavie, SYSTRAN a développé le premier système Serbo-Croate --> Anglais pour le compte de l'administration américaine.
La technologie brevetée SYSTRAN a également été employée par la NASA pour le projet américano-soviétique Apollo-Soyouz en 1974-1975. Cet événement historique a préparé le terrain pour la mise en place d'un premier prototype Anglais --> Français pour la Commission européenne. Peu après, SYSTRAN était choisi par la Commission pour fournir des systèmes de traduction pour l'ensemble des paires de langues européennes. Actuellement, la Commission et de nombreuses institutions européennes utilisent 17 systèmes de traduction SYSTRAN.
SYSTRAN ne deviendra une entreprise de droit français que vingt ans plus tard, à la fin des années 80 :
1986 : GACHOT SA, société française, dont l'activité principale est la robinetterie industrielle et le contrôle des fluides, acquiert les deux sociétés de droit américain STS (anc. WTC) et LATSEC, à l'origine des développements et propriétaires exclusives de la technologie SYSTRAN, ainsi que 76% du capital de la société allemande SYSTRAN INSTITUT GmbH.
Les années 1986 à 1988 sont consacrées au développement du système et du patrimoine linguistique de SYSTRAN.
1989 : Afin d'assurer un développement efficient, il a été décidé de donner à l'activité de Traduction Automatique une structure opérationnelle et juridique autonome. GACHOT S.A. fait un apport partiel d'actif de sa branche complète d’activité « Traduction » à la société SYSTRAN S.A. Cet apport a été rémunéré par l'émission d'actions SYSTRAN S.A. au profit de GACHOT S.A., qui détient, suite à cette opération, 99,9% de son capital.
Ces informations sont tirées du document de référence 2002 de SYSTRAN S.A., année qui marque un tournant important pour la société, comme nous allons le voir en faisant quelques comparaisons entre cette année-là et l' exercice 2013.
États financiers 2002 (c'est moi qui graisse et qui souligne) :
Considéré aujourd’hui comme le premier fournisseur mondial de solutions de traduction (Source IDC, 2002), SYSTRAN propose à ses clients une offre complète de logiciels et de services.
3.2.3 La concurrence
Le secteur de la traduction automatique se caractérise par de fortes barrières à l’entrée compte-tenu des investissements nécessaires et du temps de développement nécessaire pour mettre au point ces logiciels.
Le risque de voir un nouvel entrant se positionner sur le marché est donc très faible, et la probabilité de voir se former des alliances stratégiques est élevé.
Le paysage concurrentiel de SYSTRAN s’est profondément modifié en 2002 :
- Lernout & Hauspie, société belge qui était cotée au Nasdaq (code LHSP), a fait faillite en 2001, consécutivement aux poursuites pour malversations financières engagées contre elle. Ses activités dans la traduction humaine, le groupe Mendez, ont été cédées à Bowne Global Solutions, une importante société de traduction humaine nord américaine.
- IBM a lancé au printemps 2001 une solution de traduction pour serveur, «WebSphere Translation Server» proposant 11 paires de langues.
-
Logomedia, filiale de Language Engineering Corp. cherche à développer son activité sur le marché nord américain avec un succès limité.
-
SDL International, société de traduction humaine britannique cotée au London Stock Exchange (code SDL) a racheté début 2001 l’activité de traduction « Transcend » de Transparent Language, société basée aux Etats-Unis.
-
La société allemande « Sail Labs », créée en 2001 pour reprendre des actifs de Lernout & Hauspie a fait faillite en février 2002, puis a fusionné avec deux autres sociétés suisses pour créer la société Comprendium.
-
La société russe Prompt qui commercialise en France par l’intermédiaire de la société française Softissimo des logiciels de traduction grand public pour Windows (logiciel Reverso).
Il apparaît donc qu'à l'époque, SYSTRAN est en position de monopole quasi-absolu (en dépit de la présence d'IBM sur ce segment), et notamment en ligne :
SYSTRAN a innové en 1998 en lançant le premier service de traduction sur Internet en partenariat avec AltaVista. Depuis, SYSTRAN fournit la quasi-totalité des Portails Internet ayant intégré la traduction automatique ainsi que des milliers de sites Web qui ont des liens permanents avec des sites « Powered by SYSTRAN ». La technologie SYSTRAN a fait ses preuves dans des environnements aussi exigeants en termes de trafic que les moteurs de recherche AltaVista, AOL, Compuserve, Apple Google et Lycos.
Liste des principaux Portails utilisant les moteurs de traduction SYSTRAN :
- Altavista
- AOL
- Free
- Google
- Lycos
- Voila
- Wanadoo
L’OUVERTURE DE L’ARCHITECTURE POUR RÉPONDRE AUX BESOINS DES ENTREPRISES ET AUX CONTRAINTES D'INTERNET
Début 1998, SYSTRAN fait prendre conscience à la communauté Internet de l’utilité et des capacités de la traduction automatique en fournissant sa technologie pour le service de traduction d'AltaVista : Babelfish.
Fin 2002, SYSTRAN équipe la majorité des grands portails Internet : Altavista, Google, Lycos, Wanadoo, Voila, Free...
(...)
SYSTRAN fournit SYSTRANBox à de nombreux Portails de référence comme Wanadoo, Voila, AOL, Terra, Lycos, Free, bénéficiant ainsi d’une forte visibilité sur Internet.
Pour autant, toujours convaincue que les "fortes barrières à l'entrée" continuaient de protéger son positionnement de leader monopoliste, les premiers signes de contraction du marché "historique" de SYSTRAN commençaient à percer :
Le marché de la traduction automatique est un marché en phase d’amorçage et des concurrents tels que IBM ou d’autres éditeurs de logiciels représentent une concurrence sérieuse pour SYSTRAN, d’autant plus qu’IBM dispose d’une offre globale intégrant la synthèse et la reconnaissance vocale ainsi que la traduction.
Le marché est cependant protégé par des barrières à l’entrée importantes. (...) Allied Business Intelligence estime qu’il faudrait un investissement de l’ordre de 6 à 9 MEUR pour développer un système de traduction automatique et de 0,15 à 0,30 MEUR pour l’adapter.
Pour sa part, SYSTRAN a acquis une très forte et incomparable expérience dans la fourniture de technologie clé en main pour de grandes administrations (Commission européenne, US Department of Defense), de grandes entreprises (Ford, SONY) et des sites et portails à fort trafic (Google, Altavista).
Quant à la part de C.A. générée par les portails, dont les « revenus publicitaires ... sont enregistrés sur la base des décomptes transmis par ces derniers », elle a considérablement baissé, passant de 1,8 M€ en 2000 (soit 19,35% du C.A. total à 9,3 M€) à 1,1 M€ respectivement en 2001 et 2002 (soit 13,41% du C.A. total à 8,2 M€ pour les deux exercices).
L’année 2002 est une année charnière pour SYSTRAN qui se caractérise par la confirmation des tendances observées en 2001 : contraction du marché des Portails, développement de la demande sur le marché Corporate.
Réorganisation
Afin de prendre en compte l’évolution du marché, caractérisée par la baisse sensible de l’activité Portails et le développement des ventes auprès des Grands Comptes, la Société a été réorganisée autour de deux pôles reflétant ses deux métiers de base :
- Édition de Logiciels (Software Publishing), et
- Services Professionnels (Professional Services).
Pour SYSTRAN, l'activité "Corporate" va désormais compenser l'activité "Portails", qui disparaît ainsi du bilan grâce à la "réorganisation", irrémédiablement destinée à péricliter au fil des ans, chose que confirment de manière éclatante les états financiers 2013 :
1.5.3 La concurrence
Historiquement, le secteur de la traduction automatique se caractérisait par de fortes barrières à l’entrée compte-tenu des investissements et du temps de développement nécessaires pour mettre au point ces logiciels. Le développement d’Internet et les progrès des capacités de traitement informatique ont permis aux technologies de traduction automatique statistique de faire des progrès importants. Les barrières à l’entrée sont beaucoup moins élevées que par le passé, et certains des composants technologiques permettant de développer des logiciels de traduction automatique statistique sont désormais disponibles en Open Source. Parallèlement, l’utilisation croissante des logiciels de traduction automatique par les traducteurs humains et les sociétés de traduction, se traduit par un développement du marché qui attire de nouveaux entrants. SYSTRAN doit donc désormais faire face à de nouveaux concurrents qui se sont positionnés sur ce marché en développement.
* (Google et Microsoft) représentent la plus importante menace compte-tenu :
- de leur puissance et de leurs moyens;
- de leur positionnement sur les services gratuits et les offres payantes ;
- du niveau de leurs offres commerciales qui sont très bon marché ;
- de leur positionnement technologique qui évolue vers la capacité à personnaliser les logiciels ce qui était jusqu’à maintenant un élément différenciant de SYSTRAN.
* Les fournisseurs de service de traduction
Depuis plusieurs années, les fournisseurs de service de traduction s’intéressent de plus en plus à la technologie et de nouvelles alliances naissent.
Ainsi, la société SDL, qui est l’un des premiers fournisseurs de service de traduction dans le monde, a racheté en 2010 la société Language Weaver, créée en 2002 aux Etats-Unis et financée par le fonds d’investissement In-Q-Tel. La société SDL est aussi l’éditeur du logiciel Trados et se positionne principalement sur le marché des grandes entreprises et des administrations.
De son côté le leader mondial Lionbridge a signé une alliance avec IBM qui a également développé sa propre technologie de traduction automatique.
Enfin, plusieurs sociétés fournissant des services de traductions aux entreprises ont développé des services en ligne. On peut ainsi citer la société ALS qui a lancé le service en ligne SmartMate basé sur le logiciel Open Source Moses.
* Les acteurs historiques
Il existe en outre un certain nombre d’acteurs historiques sur le marché :
- IBM qui dispose d’une offre de traduction pour les entreprises, «WebSphere Translation Server» et développe une nouvelle génération de logiciels de traduction ;
- la société russe Promt présente sur le marché des particuliers et des entreprises ;
- Logomedia, filiale de Language Engineering Corp. est présente sur le marché nord-américain, principalement avec des offres à destination des particuliers ;
- la société allemande « Sail Labs », créée en 2001 pour reprendre des actifs de Lernout & Hauspie a fait faillite en février 2002, puis a fusionné avec deux autres sociétés suisses pour créer la société Comprendium.
* Les acteurs Open source
Le logiciel Open source Moses connait un succès croissant et de plus en plus de sociétés tentent des expériences basées sur ce logiciel qui est de fait devenu un concurrent non négligeable.
Au cours des prochaines années, le risque de voir de nouveaux entrants se positionner sur le marché et la probabilité de formation d’alliances stratégiques est élevé.
* * *
La disruption créatrice
SYSTRAN est l'exemple parfait du monopoliste balayé de la scène en une dizaine d'années parce qu'il n'a pas su anticiper les bouleversements à l'œuvre ni vu venir, ou trop tard, l' innovation disruptive de Google :
L'innovation disruptive [est] avant tout une façon de définir le processus de transformation d'un marché. Elle se manifeste par un accès massif et simple à des produits et services auparavant peu accessibles ou coûteux.
La disruption change un marché non pas avec un meilleur produit - c'est le rôle de l'innovation pure -, mais en l'ouvrant au plus grand nombre.
Or avec l'innovation Google nous avons une triple disruption sur la TA, en termes de :
- qualité (nettement supérieure à SYSTRAN)
- audience (service accessible à des milliards d'internautes)
- coût (de gratuit à 20€ par million de caractères de texte !)
Le tournant a lieu le 22 octobre 2007, jour où Google abandonne définitivement les produits SYSTRAN pour les siens, SYSTRAN n'étant plus désormais qu'un concurrent parmi d'autres, et sûrement pas le mieux placé...
* * *
Les concurrents de SYSTRAN en 2014
Ayant déjà longuement parlé de Google & TA et testé la plateforme TA de Microsoft, je vais tenter d'analyser le positionnement des concurrents de SYSTRAN aujourd'hui en m'inspirant de la classification retenue par la société dans son bilan 2013 :
- Les fournisseurs de services linguistiques
- Les acteurs historiques
- Les systèmes Open source & Crowdsourced
I. Les fournisseurs de services linguistiques
En 2013 SYSTRAN mentionne uniquement SDL (avec iMT), Lionbridge ( en collaboration avec IBM) et Applied Language Solutions (avec SmartMate), mais en réalité, sans compter les acteurs historiques que nous verrons plus loin, la liste des entreprises impliquées dans la TA (qui devrait générer un CA 2019 de près de 5 Mds € au niveau mondial) est longue : Asia Online, Babylon, Bitext, Capita TI, Cloudwords, Hewlett Packard, Kilgray, Language I/O, Lighthouse IP Group, Lingo24, Lingotek, Linguasys, Moravia, MultiCorpora, Oracle, Pangeanic, Precision Translation Tools, RWS Group, TAUS, Tauyou, Tilde, Translate Plus, Translations.com (= Transperfect, OpenText), Welocalize Inc, WorldLingo, etc.
II. Les acteurs historiques
Mis à part ceux qui ont disparu ou ont été absorbés, les quatre acteurs historiques concurrents cités par SYSTRAN autant en 2002 qu'en 2013 sont IBM, Promt ( Reverso-Softissimo), Language Engineering Corp. (via sa filiale Logomedia), et Comprendium ( Lucy Software aujourd'hui). Il est d'ailleurs bizarre que SYSTRAN mentionne en 2013 un concurrent qui n'existe plus, mais bon, cela n'est qu'un exemple des nombreuses infos dépassées qu'on trouve dans ce bilan ! Ceci dit, à l'exception d'IBM, je ne vois aucune des trois autres sociétés citées capable de jouer un rôle de premier plan dans la TA des années à venir, le futur nous le dira...
III. Les systèmes Open source & Crowdsourced
Moses est le seul logiciel Open source indiqué par SYSTRAN comme " concurrent non négligeable", même si la société reconnaît qu' [a]u cours des prochaines années, le risque de voir de nouveaux entrants se positionner sur le marché et la probabilité de formation d’alliances stratégiques est élevé.
Au moins elle a parfaitement raison sur ce point, car nous allons le voir, ces plateformes de TA sont nombreuses et diversifiées, et s'étendent même à d'autres usages, comme le cycle "reconnaissance automatique de la parole / TA / synthèse vocale" ( Speech-to-Text, Text-to-Speech), ou encore aux applications de " Speech Analytics" :
- analyse ponctuelle de gros corpus de dialogues enregistrés à des fins de fouille de données comme, par exemple, le diagnostique d'un problème constaté ou encore l'extraction de connaissances sur les performances des centres d'appels et les comportements des utilisateurs ;
- analyse périodique d'un centre d'appel afin de proposer des outils de surveillance ou "monitoring" du fonctionnement du centre.
Un autre emploi, lié à l'explosion de la production de contenus sur Internet (et je ne parle pas de traduction de sites Web à la volée), comme illustré sur la diapo ci-dessous (même si en 2014, selon moi, on pourrait tranquillement doubler la quantité de mots générés par les utilisateurs, vu la croissance exponentielle des différents réseaux sociaux), concerne le data mining à des fins marketing : pour avoir une idée globale de l'impact de leurs produits, ainsi que des humeurs de leurs clients ou des tendances qui se dessinent, les multinationales automatisent la traduction de ces données pour centraliser l'info dans une seule langue (en général l'anglais, bien sûr, mais ça peut être n'importe quelle autre langue) à propos de leurs marques, en traduisant les interventions / commentaires / critiques mentionnant leurs produits dans les réseaux sociaux. Les infos ainsi collectées à partir de cette "conversation mondiale" servent ensuite à réagir / anticiper au niveau des prises de décision...
Or la traduction automatique est indispensable et irremplaçable pour traiter de tels volumes, et vu que toutes les sociétés ne sont pas prêtes à internaliser ce genre de travail, elles ont souvent recours à des sous-traitants comme Lionbridge ou autres. Il y a là un marché plein d'avenir !
Autre exemple, eBay illustrera le mois prochain " The eBay Machine Translation Initiative", mise en œuvre l'année dernière, qui consiste à développer des outils de traduction automatique pour booster son commerce en particulier dans les pays BRICS. Les acheteurs bénéficient ainsi de traductions pour consulter les annonces des vendeurs dans la langue de leur choix et pouvoir communiquer en temps réel (voir cet article sur Wired).
Voici donc, pour compléter cet inventaire à la Prévert, une liste de sociétés susceptibles d'utiliser la traduction automatique et de projets open source ou faisant intervenir la participation communautaire.
Sociétés
Verint, BBN-Avoke, Autonomy eTalk, Duolingo, CallMiner, Dotsub, Nuance, OpenAmplify, Gengo, Rovi Corp., STAR Transit intègre les différents systèmes de TA, etc.
Dans son étude 2013 sur l'état et les potentialités des marchés européens des technologies de la langue, LT- Innovate estime qu'il y a environ 500 entreprises en Europe qui innovent en développant ou en intégrant ces technologies, mais ce sont pour le plus des PME qui restent cantonnées sur leur marché linguistique national, représentant chacun entre 70 et 80 millions de locuteurs, voire moins, contre plus de 500 millions de citoyens européens au total. Une fragmentation en décalage avec les capacités d'un déploiement en mode cloud, ce qui donnera probablement lieu à un mouvement de concentration, à l'instar des grands groupes de traduction, pour mettre les sociétés européennes - pratiquement absentes du marché de la traduction automatique ( SYSTRAN est désormais coréenne...) - en mesure d'être compétitives dans l'écosystème mondial des technologies de la langue.
Juste à titre d'exemple, et sauf erreur de ma part, parmi les acteurs français du marché de la traduction technique que j'ai recensés, seul Eurotexte (Lexcelera) propose SMART (Secure Machine-Assisted Rapid Translation), sa propre solution de TA, fortement voulue et promue par Lori Thicke, créatrice d'Eurotexte, qui est également à l'origine de Traducteurs sans frontières, soit dit en passant !
Projets
Open Source
Nous avons mentionné Moses, probablement le projet le plus en vogue, mais il faudrait citer également d'autres systèmes de traduction probabiliste, comme Pharaoh, Phrasal, Joshua et autres, utilisant des corpus parallèles, certains librement téléchargeables sur Internet ( les ressources ne manquent pas), ou encore Matrax (Xerox), Cunei pour les langues asiatiques, Marclator, Apertium, etc.
La dernière version disponible du Compendium des logiciels de traduction de John Hutchins dresse un panorama assez complet des outils linguistiques au sens large, mais on peut également consulter les archives de la traduction automatique ou voir ici pour une brève chronologie de la TA...
Crowdsourced
Les grands réseaux sociaux tels que Facebook, Twitter, LinkedIn et autres, mais aussi Google et Microsoft, nourrissent leurs systèmes en partie grâce à la participation active, volontaire et gratuite des utilisateurs, qui peuvent corriger, critiquer, alimenter à volonté les gigantesques mémoires de traduction de ces mastodontes du Web, déployées à très grande échelle ( very large scale), chose hors de portée des fournisseurs de services linguistiques traditionnels.
À titre de comparaison, Lionbridge disposerait d'environ 52 000 mémoires de traduction individuelles, ce qui est déjà enviable, mais sans commune mesure avec la puissance d'un Facebook comptant 1,3 milliard de membres actifs ! Pour autant, par le biais de partenariats, tel que celui avec TAUS, la montée en puissance est assurée...
Dans d'autres registres, The Rosetta Foundation soutient le projet SOLAS, AT&T Research le projet ChoiceWords, destiné à améliorer la TA en y intégrant l'interaction humaine, Reverso le projet FAUST, le CRTL le projet PORTAGE de Terminotix, Translate House la mémoire de traduction " large scale" amaGama pour les langues sud-africaines, sans oublier Meedan pour l'arabe, iTranslate4EU, le projet Memsource Cloud, la localisation d' Apache Open Office ( projet initialement supporté par SUN), et ainsi de suite...
Enfin, hors catégories, un protagoniste absolu des technologies linguistiques, impossible à passer sous silence, est la DARPA, comme je le mentionnais dès 2007 :
Dans son rapport 2007 de planification stratégique, la DARPA, mieux connue pour être à l'origine du défi Internet, nous annonce que l'un de ses développements clés à l'horizon 2010 va porter sur le traitement des langues, et plus spécialement sur une traduction automatique fiable en temps réel : Real-Time Accurate Language Translation, qui ne nécessitera plus l'intervention de traducteurs-interprètes humains. Directement du média à l'utilisateur !

Page 33 du rapport, fin de la section 3.7. Ce mode de traitement, qui fait partie du programme GALE (Global Autonomous Language Exploitation), prévoit trois phases :
- la transcription
- la traduction
- la distillation
La première étape pour pouvoir exploiter les données audio en langue étrangère à des fins de traduction consiste à convertir les discours en texte, c'est la transcription. Les américains nomment ça Speech to Text Transcription (STT). Après quoi le texte est traduit puis « distillé », l'ensemble des opérations étant automatisé par des moteurs de traitement (2.2 Transcription Engine ; 2.3 Translation Engine ; 2.4 Distillation Engine). Aperçu de ce dernier concept :
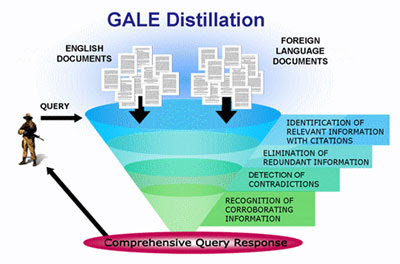
L'objectif est de parvenir à de très hauts niveaux de performances : 95% de fiabilité et 90-95% de cohérence/justesse sur les traductions depuis l'arabe et le chinois vers l'anglais, afin de pouvoir extraire et fournir des informations clés aux décideurs ayant un degré de pertinence égalant voire dépassant celui des humains.
Si on évalue grossièrement à 60% le degré de fiabilité des systèmes actuels, on peut se faire une idée des progrès qui seront accomplis. Disons qu'après 50 ans de tâtonnements de la recherche en TA, l'évolution sera significative dans les années à venir. Avec des conséquences qu'on peut aisément deviner pour les traducteurs, qui n'en sont plus à une révolution près ! D'ailleurs c'est écrit en toutes lettres :
GALE engines perform both of these processes in a completely automated fashion, without the intervention of human linguists.
Nous voilà fixés, si certains nourrissent encore quelques doutes. Car une fois au point, nous savons très bien que les technologies développées par les militaires sont ensuite industrialisées pour des usages civils. Il serait donc temps que nous remémorions le vieil adage : « Un traducteur averti en vaut deux... »
À noter que sur l'année 2007, la Darpa a budgété +84 millions US$ aux technologies de traduction du langage (language translation technologies), soit 7 millions par mois, ce qui s'appelle "se donner les moyens" ! (source : Human Language Technologies for Europe, p. 32, PDF - 7,7 Mo)
* * *
Juste pour donner une idée de l'état de l'art en la matière, voici la synthèse d'un rapport publié par l'OTAN, Research & Technology Organisation, sur « La mise en œuvre des technologies de la parole et du langage dans les environnements militaires » (RTO-TR-IST-037) (PDF en anglais, 4,3 Mo) :
Les communications, le commandement et contrôle, le renseignement et les systèmes d’entraînement font de plus en plus appel à des composants issus des technologies vocales et du traitement du langage naturel : il s’agit de codeurs vocaux, de systèmes C2 à commande vocale, de la reconnaissance du locuteur et du langage, de systèmes de traduction, ainsi que de programmes automatisés d’entraînement. La mise en œuvre de ces technologies passe par la connaissance des performances des systèmes actuels, ainsi que des systèmes qui seront disponibles dans quelques années.
Etant donné l’intégration de plus en plus courante des technologies vocales et du traitement du langage naturel dans les systèmes militaires, il est important de sensibiliser tous ceux qui travaillent dans les domaines de la conception des systèmes et de la gestion des programmes aux capacités, ainsi qu’aux limitations des systèmes de traitement de la parole actuels. Ces personnes devraient également être informées de l’état actuel des travaux de recherche dans ces domaines, afin qu’ils puissent envisager les développements futurs. Cet aspect prendra beaucoup d’importance lors de la considération d’éventuelles améliorations à apporter à de futurs systèmes militaires.
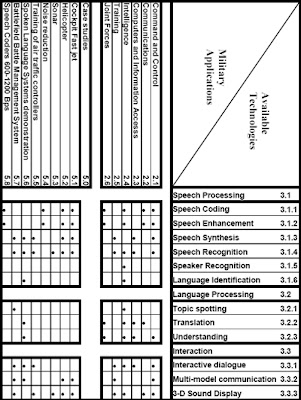
Les textes contenus dans cette publication comprennent des communications sur l’état actuel des connaissances dans ce domaine, ainsi que sur des travaux de recherche en cours sur certaines technologies de la parole et du langage, à savoir : les techniques et les normes d’évaluation, la reconnaissance de la parole, l’identification linguistique, et la traduction.
Technologies déjà disponibles :
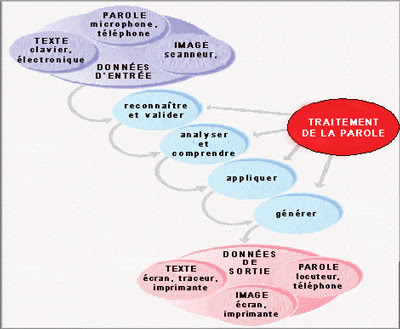
Décomposition du traitement de la parole (PDF, 12 Mo) :
* * *
Donc, depuis GALE, les derniers projets en cours de la DARPA susceptibles d'impacter la TA et les technologies de la langue sont BOLT ( Broad Operational Language Translation) :
BOLT is part of DARPA’s broader efforts to provide language translation in support of Defense and National Security requirements ranging from phrase translation to the scanning and translation of large data sets of voice, video and print.
probablement en attente d'être reconduit, DEFT ( Deep Exploration and Filtering of Text) et XDATA ( XDATA is developing an open source software library for big data to help overcome the challenges of effectively scaling to modern data volume and characteristics).
Gageons que nous en reparlerons...
* * *
CONCLUSION
Pendant une bonne cinquantaine d'années, la traduction automatique a donné quelques résultats dignes d'intérêt : TAUM-METEO, LOGOS, ALPS, ENGSPAN-SPANAM, METAL, GLOBALINK, TITUS, CULT, PaTrans, SUSY et d'autres, etc., mais la traduction automatique à base de règles ( RBMT : Rule-Based Machine Translation), qui a été la technologie dominante, a aussi marqué trop longtemps le pas en montrant toutes ses limites...
Il faudra attendre Google et l'évolution de son système de traduction automatique statistique ( SMT : Statistical machine translation, la deuxième grande famille de TA) pour que l'univers de la traduction automatique se réveille d'une longue torpeur et commence à foisonner.
Aujourd'hui, l'idée est de développer des systèmes de TA hybrides en combinant le meilleur des deux mondes, si possible dans le cloud et en s'appuyant sur les puissances de calcul phénoménales qui s'accroissent de manière exponentielle.
Donc en essayant de donner un aperçu de la diversité des acteurs impliqués et des multiples technologies en jeu (entre les Corpus-based, Dictionary-based, Example-based, Human-Aided, Interlingual, Knowledge-Based, Pattern-based, Phrase-based et autres Transfer-based Machine Translation ou Machine-Aided Human Translation, ...), j'espère que le message sera passé : la traduction automatique a mis presque 80 ans pour en arriver là, les principes actuels étaient déjà fixés à la fin des années 1940 / début des années 1950, mais à présent nous y sommes, et toutes les conditions sont réunies pour qu'à l'avenir elle exprime à plein son potentiel incommensurable. Nous en reparlerons dans 20 ans lorsqu'elle fêtera son centenaire !
En attendant les traducteurs devront se familiariser et apprendre à faire avec, en considérant la TA non pas comme une menace ou un concurrent déloyal, mais comme une alliée, voire un complément à forte valeur ajoutée pour leur activité !
Lors des formations marketing pour traducteurs et interprètes qu'il m'arrive de dispenser, j'insiste toujours sur un point fondamental, selon moi : le marketing doit devenir, pour les étudiants comme pour les traducteurs/interprètes, de métier ou en début de carrière, un instrument de plus à intégrer dès le départ à leur boîte à outils, au même titre que les environnements de traduction ou autres, pour les accompagner ensuite tout au long de leur vie professionnelle.
Désormais, il en va de même pour la traduction automatique.
Copyright © ProZ.com, 1999-2025. All rights reserved.
|




