Pre-translation: a weird problem De persoon die dit onderwerp heeft geplaatst: Elif Baykara Narbay
|
|---|
Hello, all!
I have a weird problem regarding pre-translation. I have searched through the fora and followed the relevant steps proposed therein.
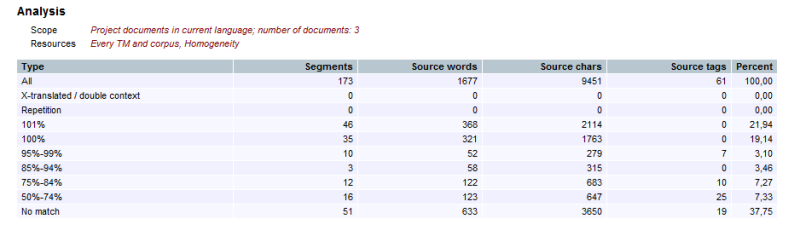
I created a project of 3 Word files (173 segments) as usual. I added the TM I always use with such projects. And I performed an analysis of the project (all segments were empty). I attached the screenshot of the analysis below: there are some matches, about 45% of all segments is matched either as 100%, 101% or 95-99%.
<... See more Hello, all!
I have a weird problem regarding pre-translation. I have searched through the fora and followed the relevant steps proposed therein.
I created a project of 3 Word files (173 segments) as usual. I added the TM I always use with such projects. And I performed an analysis of the project (all segments were empty). I attached the screenshot of the analysis below: there are some matches, about 45% of all segments is matched either as 100%, 101% or 95-99%.
Then I pre-translated the file for exact matches: no change at all.
I am puzzled. This is not an urgent question, I will complete the project without pretranslation anyway. But I would like to hear your opinions on the subject.
Best,
Elif
 ▲ Collapse
| | | | Anthony Green 
Italië
Local time: 07:59
Italiaans naar Engels
+ ...
| what is puzzling you? | Oct 23, 2016 |
Hello Elif
I don't understand what you are puzzled by as it seems fairly normal. Can you explain?
| | | | | None of the segments were pre-translated. | Oct 23, 2016 |
Probably I am missing something very basic, but since I have some exact matches (e.g., 35 segments are matched by 100%), I expect them to be pre-translated. At least this is what happened before in the previous projects where I created the project, in the same way, using the same TM.
Elif
| | | | | "Good match" | Oct 23, 2016 |
Out of curiosity, what happens if you pre-translate the documents using the "Good match" option?
| | |
|
|
|
Anthony Green
Italië
Local time: 07:59
Italiaans naar Engels
+ ...
Elif Baykara wrote:
since I have some exact matches (e.g., 35 segments are matched by 100%), I expect them to be pre-translated.
Elif
Oh yes, I understand. Yes that's strange.
If you go into one of the segments with a match (100% or otherwise), do you see the red field in the Translation Results pane corresponding to the match?
| | | | | Now I did this: | Oct 23, 2016 |
As a final check, I did the following:
1) I created a new project with the same 3 Word files. This time, it gave 179 segments in total (it was 173).
2) I used the same TM as before.
3) I analyzed the project: I got pretty much the same result.
4) I pre-translated for exact matches: none of the segments were changed (all segments are still empty).
5) I pre-translated for good matches: none of the segments were changed (all segments ... See more As a final check, I did the following:
1) I created a new project with the same 3 Word files. This time, it gave 179 segments in total (it was 173).
2) I used the same TM as before.
3) I analyzed the project: I got pretty much the same result.
4) I pre-translated for exact matches: none of the segments were changed (all segments are still empty).
5) I pre-translated for good matches: none of the segments were changed (all segments are still empty).
6) I pre-translated for any match: 6 of the segments were pre-translated (all other segments are still empty). Pretranslated segments contain either a number or a single word. ▲ Collapse
| | | | | I can't see the 100% matches at all. | Oct 23, 2016 |
Anthony Green wrote:
Elif Baykara wrote:
since I have some exact matches (e.g., 35 segments are matched by 100%), I expect them to be pre-translated.
Elif
Oh yes, I understand. Yes that's strange.
If you go into one of the segments with a match (100% or otherwise), do you see the red field in the Translation Results pane corresponding to the match?
I filtered the files for fuzzy, 100% and 101% matches. There are some with 99% or 66%, for example. But no, I don't see any 100% or 101% matches.
| | | | | Homogeneity? | Oct 23, 2016 |
I have noticed that for your analysis you have Homogeneity turned on — maybe it lists high-percent matches within the document itself, and not from the TM? Try to re-run the analysis with Homogeneity field unchecked and let us now about the results.
Greetings,
K.
| | |
|
|
|
Kuba Kościelniak wrote:
I have noticed that for your analysis you have Homogeneity turned on — maybe it lists high-percent matches within the document itself, and not from the TM? Try to re-run the analysis with Homogeneity field unchecked and let us now about the results.
That might well be the solution to this mystery
| | | |
I performed two analyses, with and without homogeneity on. However, I have already started with the translation and I have 23 confirmed segments.
I pre-translated using this updated TM and all 23 segments were pre-translated. Comparing the two analyses also confirms that you are right.
I believe that I should not postpone a training on memoQ anymore I have a faint idea of homogeneity, but I have never ... See more
| | | |
Mirko Mainardi wrote:
Kuba Kościelniak wrote:
I have noticed that for your analysis you have Homogeneity turned on — maybe it lists high-percent matches within the document itself, and not from the TM? Try to re-run the analysis with Homogeneity field unchecked and let us now about the results.
That might well be the solution to this mystery
When Homogeneity is on, there are no repeats, instead the "repeats" are counted as 100 and 101%.
From your analyses, 687+139+2 = 507+321
Why:
MemoQ scans an unknown segment that is repeated later: counts it as normal, ie 0% if there is no match in the TM.
MemoQ later scans the same segment: with Homogeneity On, MemoQ says that it's already "virtually" translated (from the scan above), so it's a 100% (or 101%). With Homogeneity Off, MemoQ counts it as a repeat.
Homogeneity counts "internal fuzzies" in a text:
Homogeneity Off, TM empty
"I have a dog" 0% match
"I have a frog" 0% match
Homogeneity On, TM empty
"I have a dog" 0% match
"I have a frog" 85% match (or something)
Therefore the discrepancy in fuzzy bands too in your analyses with and without Homogeneity.
Homogeneity On = Lower weighted wordcount
Philippe
Edit for errors in the English
[Edited at 2016-10-23 17:16 GMT]
| | | | | Thank you Philippe! | Oct 23, 2016 |
You have explained it just the way I could understand.
I have only a few clients for which I have agreed to apply a discount for fuzzy matches. I use these analyses mainly to assess the projects so that I know what is waiting for me. So they serve just as a guide for me.
I am glad that I noticed this problem/feature relatively early and on a short project. In this way, I can make more accurate assessments and I will be more happy in general  ... See more ... See more You have explained it just the way I could understand.
I have only a few clients for which I have agreed to apply a discount for fuzzy matches. I use these analyses mainly to assess the projects so that I know what is waiting for me. So they serve just as a guide for me.
I am glad that I noticed this problem/feature relatively early and on a short project. In this way, I can make more accurate assessments and I will be more happy in general
Best,
Elif ▲ Collapse
| | |
|
|
|
| Try checking "perform fragment assembling" | Oct 23, 2016 |
Did you previously use the "copy source to target" function? That might prevent segments being pre-translated sometimes. The segments need to be empty for it to work.
Is "Perform Segment assembling" (or something like that) checked?
Apparently it needs to be checked in order for Pre-Translation to work. I learned this from MemoQ support when I had the same problem once.
By the way, the above setting is one example of user-unfriendly design. The name tells the use... See more Did you previously use the "copy source to target" function? That might prevent segments being pre-translated sometimes. The segments need to be empty for it to work.
Is "Perform Segment assembling" (or something like that) checked?
Apparently it needs to be checked in order for Pre-Translation to work. I learned this from MemoQ support when I had the same problem once.
By the way, the above setting is one example of user-unfriendly design. The name tells the user nothing at all about what the setting does and what it is needed for. It definitely would never have occurred to me to check this option just to get Pre-Translation to work. "Fragment assembling" doesn't sound like something to do with TM matches. I would have guessed it to be related to machine translation.
[Edited at 2016-10-23 19:09 GMT] ▲ Collapse
| | | | LEXpert
Verenigde Staten
Local time: 00:59
Lid 2008
Kroatisch naar Engels
+ ...
| Are the pre-translated segments confirmed before re-running the analysis? | Oct 23, 2016 |
So you ran an analysis, then pretranslation, then re-ran the analysis?
Just running the pretranslation won't change the analysis unless you confirm the pre-translated segments, otherwise nothing in your TM is changing.
| | | | | 101% march pre-translation problem and a good idea | Jan 16, 2019 |
Hello, everyone!
I have a similar problem. I have 100% and 101% matches in the TM, they appear on the right if I go to the specific segment, but when I pre-translate the document, Memoq simply does not translate these segments. Less matching segments are translated, though.
I tell you the circumstances, too, as I also found something that might be helpful for many freelance translators. Althoug Memoq can be used on two computers with one licence, the user can't work on ... See more Hello, everyone!
I have a similar problem. I have 100% and 101% matches in the TM, they appear on the right if I go to the specific segment, but when I pre-translate the document, Memoq simply does not translate these segments. Less matching segments are translated, though.
I tell you the circumstances, too, as I also found something that might be helpful for many freelance translators. Althoug Memoq can be used on two computers with one licence, the user can't work on the same document on both, if the project is not on a server. Freelance translators typically have no server background. I just had an idea and it works: Through a TM stored on Language Terminal it is possible to "transfer" the translations from the one computer to the other. When I change from my laptop to the desktop, I just pre-translate the document, and the segments translated on the laptop will get pre-translated on the desktop and vice versa. I am sure it works normally, and is very helpful. But in my case pre-translation of 100-101% matches does not work at all.
Any idea? ▲ Collapse
| | | | To report site rules violations or get help, contact a site moderator: You can also contact site staff by submitting a support request » Pre-translation: a weird problem | Trados Studio 2022 Freelance | The leading translation software used by over 270,000 translators.
Designed with your feedback in mind, Trados Studio 2022 delivers an unrivalled, powerful desktop
and cloud solution, empowering you to work in the most efficient and cost-effective way.
More info » |
| | Anycount & Translation Office 3000 | Translation Office 3000
Translation Office 3000 is an advanced accounting tool for freelance translators and small agencies. TO3000 easily and seamlessly integrates with the business life of professional freelance translators.
More info » |
|
| | | | X Sign in to your ProZ.com account... | | | | | |












